Pub-sub System¶
Pub-sub systems like Kafka and Kinesis expose a publish-subscribe interface atop partitioned logs. We describe the implementation of a pub-sub system using Confluo that enables high publish and subscribe throughput for messages via lock-free concurrency.
Implementation¶
Our distributed messaging system implementation employs Kafka’s interface and data model — messages are published to or subscribed from
"topics
", which are logically streams of messages. The system maintains a collection of topics, where messages for each topic are stored across a user-specified number of Confluo shards.
In our implementation, each shard exposes a basic read and write interface. The publishers write messages in batches to shards of a particular topic, while subscribers asynchronously pull batches of messages from these shards. Similar to Kafka design, each subscriber keeps track of the objectId for its last read message in the shard, incrementing it as it consumes more messages. The key benefits of using Confluo for storing messages include:
- The freedom from read-write contentions, and lock-free resolution of write-write contentions.
- Confluo provides an efficient means to obtain the snapshot of an entire topic, unlike Kafka.
- Support for rich online and offline queries on message streams beyond just publish and subscribe.
Compared Systems and Experimental Setup¶
We compare the performance for our pub-sub implementation against Apache Kafka. Since both systems are identical in terms of scaling read and write performance via multiple partitions, we ran our experiments on a single r3.8xlarge instance, using a single topic with one log partition for both systems. Reads and writes were performed for 64 byte messages, and concurrent subscribers in both systems belong to different subscriber groups, i.e., perform independent, uncoordinated reads on the partition. We mount Kafka’s storage on a sufficiently sized RAM disk, ensuring that both systems operate completely in memory.
Results¶
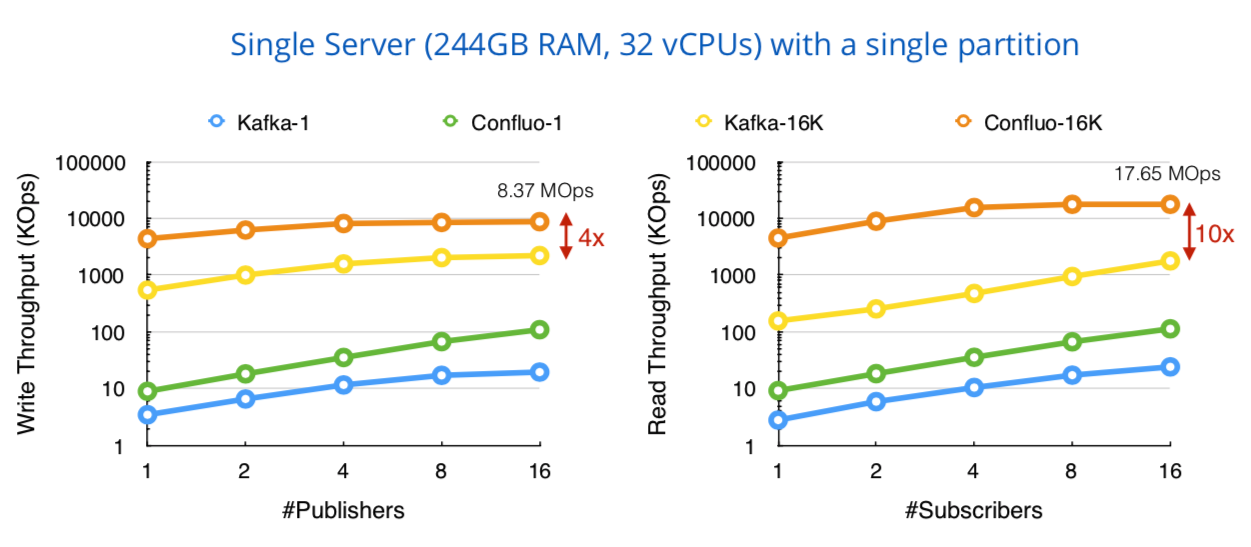 Figure: Confluo observes close to linear write
throughput scaling with #publishers as opposed to Kafka’s sub-linear
scaling, while both systems observe close to linear read throughput scaling
with #subscribers (both axes are in log-scale).
Figure: Confluo observes close to linear write
throughput scaling with #publishers as opposed to Kafka’s sub-linear
scaling, while both systems observe close to linear read throughput scaling
with #subscribers (both axes are in log-scale).
Since Kafka employs locks to synchronize concurrent appends, publisher write throughput suffers due to write-write contentions (Figure (left)). Confluo employs lock-free resolution for these conflicts to achieve high write throughput. Larger batches (16K messages) alleviate locking overheads in Kafka to some extent, while Confluo approaches network saturation at 16K message batches with over 4 publishers. Since reads occur without contention in both systems, read throughput scales linearly with multiple subscribers (Figure (right)). Confluo achieves higher absolute read throughput, presumably due to system overheads in Kafka and not because of a fundamental design difference. As before, read throughput for Confluo saturates at 4 subscribers and 16K message batches due to network saturation.